NHR@FAU has recently installed its new GPU cluster “Alex”, which is currently undergoing user-side testing until it is ready for general use. Alex has a total of 192 Nvidia A100 and 304 Nvidia A40 GPGPUs that will be available nation-wide soon; we decided to run some GROMACS benchmarking tests of MD simulations of varying size to compare the new GPU hardware to that already available in TinyGPU. The benchmark systems are identical to the ones we used for investigating the speedup of NVIDIA GPUs vs Intel Xeon Ice Lake.
Benchmarks
- R-143a in hexane (20,248 atoms) with very high output rate,
- a short RNA piece with explicit water (31,889 atoms),
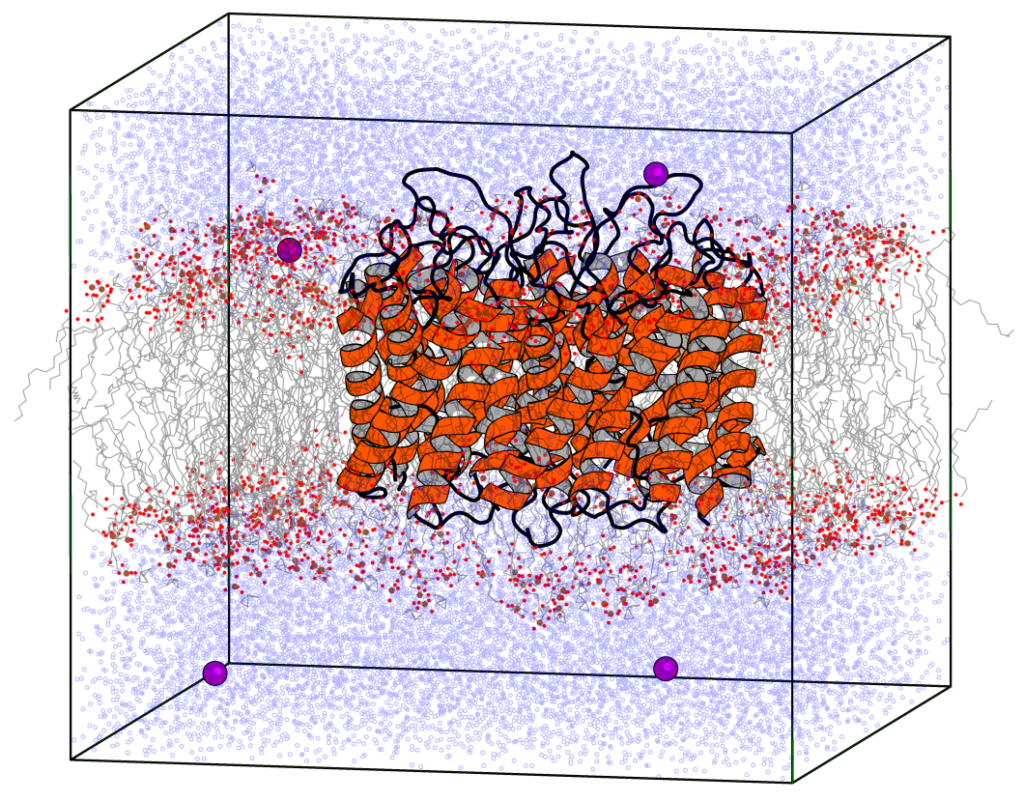
- a protein inside a membrane surrounded by explicit water (80,289 atoms),
- a protein in explicit water (170,320 atoms),
- a protein membrane channel with explicit water (615,924 atoms), and
- a huge virus protein (1,066,628 atoms).
For running these benchmarks with GROMACS2021 on a GPU , the following command was executed:
$ gmx mdrun -v -s $benchmark.tpr -nb gpu -pme gpu -bonded gpu -update gpu \ -ntmpi 1 -ntomp $ntomp -pin on -pinstride 1 -nsteps 200000 -deffnm $benchmark_name
This offloads all possible calculations to the GPU and pins the threads to the host CPU; the number of OpenMP threads depends on how many CPU cores are available per GPU (i.e., 4 for our GTX1080, GTX1080TI, 8 on RTX2080TI, V100, and RTX3080, and 16 on the A40 and A100 in Alex). On TinyGPU and Alex, several GPUs are combined with one host CPU, i.e., each GPU has access only to a fraction of the host. Depending on the hardware, different GROMACS versions were used: 2021.1 for all GPU types available in TinyGPU, version 2021.3 on A40 in Alex, and version 2021.4 on A100 in Alex.
Since GROMACS may require considerable CPU processing power (depending on the case at hand), the GPU is not the only factor that influences the performance of the benchmarks. Please also note that ECC is disabled on the A40s in Alex.
Results
| [ns/day] | system 1 | system 2 | system 3 | system 4 | system 5 | system 6 |
| GTX1080 | 62.4 | 201.6 | 62.6 | 29.3 | 7.1 | 3.5 |
| GTX1080Ti | 84.3 | 257.8 | 84.6 | 41.8 | 10.1 | 5.0 |
| RTX2080Ti | 176.2 | 508.4 | 169.3 | 79.2 | 21.8 | 11.2 |
| V100 | 163.8 | 408.7 | 153.1 | 73.3 | 23.4 | 13.2 |
| RTX3080 | 195.9 | 580.4 | 191.2 | 91.3 | 26.4 | 14.6 |
| A40 | 251.0 | 696.6 | 238.8 | 117.4 | 32.0 | 17.8 |
| A100 | 184.8 | 613.2 | 241.2 | 119.5 | 37.2 | 22.5 |
It might be tempting to just have a quick glance at these numbers and jump to the conclusion that the newest hardware will always give the best results; unfortunately, it is not quite that easy. While it is true that the NVIDIA GTX1080 and GTX1080Ti GPUs are not the current state of the art, their performance is still considerably better than that of CPU nodes from two generations ago. Also there is no consistent picture across all benchmark cases, so we will look at the results grouped by benchmark size, from small to large. To provide a point of reference, we also give speedup numbers with respect to a GTX 1080 GPU (bar graphs).
Small Systems
| [ns/day] | system 1 | system 2 |
| GTX1080Ti | 84.3 | 257.8 |
| RTX2080Ti | 176.2 | 508.4 |
| V100 | 163.8 | 408.7 |
| RTX3080 | 195.9 | 580.4 |
| A40 | 251.0 | 696.6 |
| A100 | 184.8 | 613.2 |
For system 1, the difference in speedup among the tested GPUs among the Volta and Ampere generations (starting with the RTX2080Ti) is negligible except for the A40. The very high output rate in this particular benchmark case significantly slows down the whole calculation so that even the jump from Volta to Ampere is not obvious in the data (176 ns/day with RTX2080TI and 185 ns/day with A100). Still the A40 has a noticeable advantage, which is caused by a combination of superior single-precision peak performance (which also applies to the RTX3080) and the more powerful host (16 cores per GPU instead of 8 with the RTX3080).

Similar conclusions can be drawn for the still rather small system 2, which is, however, less plagued by the overhead of a high output rate. Here, GPUs with a high single-precision peak are extremely competitive. These two benchmarks illustrate perfectly why size and type of a simulation play a crucial role in choosing the optimal hardware setup.
Medium Systems
| [ns/day] | system 3 | system 4 |
| GTX1080Ti | 84.6 | 41.8 |
| RTX2080Ti | 169.3 | 79.2 |
| V100 | 153.1 | 73.3 |
| RTX3080 | 191.2 | 91.3 |
| A40 | 238.8 | 117.4 |
| A100 | 241.2 | 119.5 |
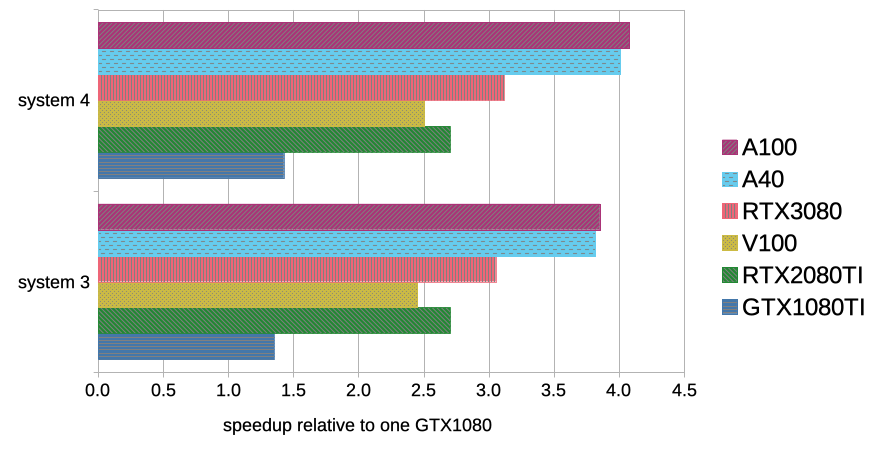
There are two notable points regarding the benchmark results for systems 3 and 4: (1) the performances across Volta-generation GPUs (RTX2080Ti and V100) is quite similar and (2) the results for the A40 and the A100 are nearly identical.
As most simulations in GROMACS are done in single precision mode, it is really not necessary to use the professional V100 GPU that is also capable of doing calculations in double precision. Therefore, it is entirely sufficient to request a random GPU via --gres=gpu:1 for running simulations on the SLURM nodes of TinyGPU. In addition, jobs that do not request a specific GPU type might not have to wait in the queue for a long time but will be assigned to the next available GPU instead.
The same is true for the newer GPU versions available in our Alex cluster because there is not much difference in performance between the A40 and the A100. At the moment, we still have to decide how users will be able to request a random GPU on Alex but this option will be documented as soon as possible in the “Batch processing” part of our Alex documentation.
Large Systems
| [ns/day] | system 5 | system 6 |
| GTX1080Ti | 10.1 | 5.0 |
| RTX2080Ti | 21.8 | 11.2 |
| V100 | 23.4 | 13.2 |
| RTX3080 | 26.4 | 14.6 |
| A40 | 32.0 | 17.8 |
| A100 | 37.2 | 22.5 |
The two largest benchmark cases 5 and 6 contain roughly 616,000 and 1,000,000 atoms, respectively. Not many of our users look at systems as large as these on a regular basis but we already came across some of those simulation setups on our clusters. In addition, we have to keep in mind that some of those really large systems might actually benefit from a multi-GPU setup but this has to be checked separately for each case.
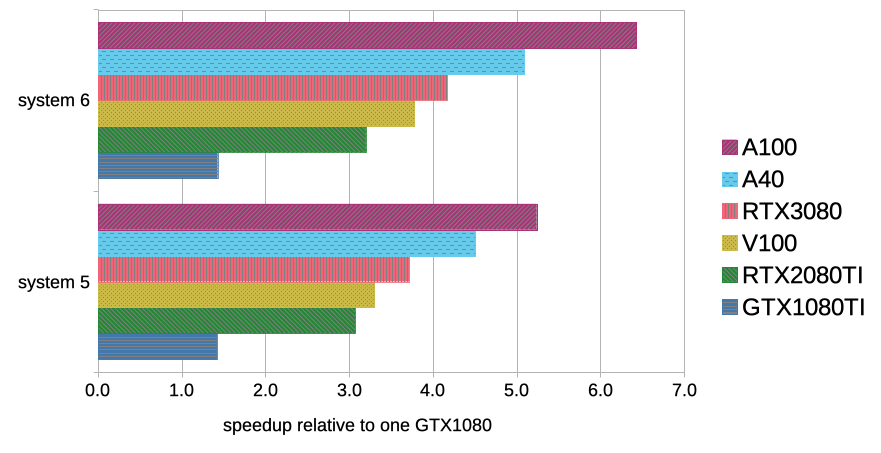
Again, we can see that there are only small differences in performance between the two RTX cards and the V100. Switching to our newest GPUs with Ampere architecture, it is obvious that the large systems can take advantage of the great number of available CUDA cores and the large memory bandwidth, together with the larger number of CPU cores per GPU.
NHR@FAU Recommendation
Small systems with fewer than 50,000 atoms should preferably be sent to TinyGPU and request a random GPU via --gres=gpu:1. The same is true for medium-sized systems with up to 500,000 atoms but these are also perfect for our A40s in Alex. We must stress again that it is not only the GPU type that matters; the larger number of CPU cores per GPU on the A40 and A100 nodes in Alex can make a decisive difference. If in doubt, perform benchmark testing first to find out which hardware performs best for your particular case; the same is true for possible multi-GPU runs. There may even be cases where it is worthwhile to use CPUs only. We will present CPU results for our new Fritz cluster soon.
We are eager to help with all these activities. Do not hesitate to contact us.
Contact us
- Email: hpc-support@fau.de