Very low bit rate speech coding is very challenging with classical coding techniques. Recently neural networks have started to fill this gap. In this work, we design Generative Adversarial Networks for coding of high-quality speech at low bit rates and low complexity. In particular we focus on how to reduce the model computational complexity, which enables its deployment on edge devices.
Motivation and problem definition
Speech coding enables the compression of speech waveform for communication and many other applications. With classical techniques it is possible to produce intelligible speech at very low bit rate, but this sounds robotic and unnatural. Neural vocoders such as WaveNet can produce high-quality speech from highly compressed inputs.
These models permit to approach the problem of speech coding from the data-driven perspective. Most of the solutions that can be found in literature suffer various disadvantages, which make them not suitable for the deployment in real-world scenarios. The primary issue is often computational complexity and generalization issues, and we set up to solve these.
Methods and codes
In our approach, we use Generative Adversarial Networks (GANs) for synthesizing the speech from a compressed bitstream. The bitstream can be either obtained from a classical speech encoder or be learned by an encoder neural network. We implement feature extraction (e.g. mel-spectrogram, MFCC, pitch, …), encoding, quantization (e.g. using classical methods or learned through a vector quantized auto-encoder), and decoding in python. The models are implemented in PyTorch and trained on large speech datasets such us VCTK and LibriTTS.
Results
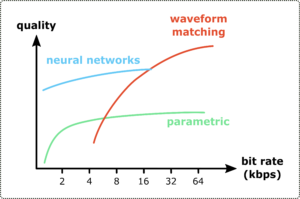
We can show that our GAN coders can achieve the same speech quality as classical speech codecs using only half of the bit rate or even less. We can configure our model in such a way that enables frame-by-frame generation, which is crucial for low-delay communications scenarios. Finally, we can reduce the complexity of our model using, among other techniques, low rank approximations of the convolutional layers, making it suitable for deployment on edge CPUs.
Outreach
This research is in part a follow-up project to the publication:
- Mustafa, A., Büthe, J., Korse, S., Gupta, K., Fuchs, G., & Pia, N. (2021, October). A Streamwise Gan Vocoder for Wideband Speech Coding at Very Low Bit Rate. In 2021 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) (pp. 66-70). IEEE.
And various other publications are planned.
Researcher’s Bio and Affiliation
Nicola Pia studied mathematics at the University of Cagliari, where he got his PhD under the supervision of Professor Gianluca Bande and Professor Dieter Kotschick from the Ludwig-Maximilian-University Munich. Since 2019, he works as a researcher in the field of AI and speech processing at the AudioLabs at Fraunhofer IIS in Erlangen.
Contact:
Nicola Pia International Audio Laboratories Erlangen Friedrich-Alexander-Universität Erlangen-Nürnberg & Fraunhofer-Institut für Integrierte Schaltungen (IIS)
Mainly used HPC resources at RRZE
Alex Cluster