
Since June 2020, the Top500 list is led by the supercomputer Fugaku, which comprises over 7.5 million Fujitsu A64FX cores. Besides their raw computational power, the cores are equipped with features that support parallel execution on the systems: hardware barrier, sector cache (cache partitioning), and prefetch distance. The hardware barrier is of special interest because synchronization among threads and processes is a crucial but time-consuming operation in parallel processing. The hardware barrier is managed at kernel level and exposes its features to user space with system calls. Although Fujitsu has published the user space library as open source, the management part (i.e., the kernel module) is only available in the FUJITSU Software Technical Computing Suite under closed license.
Although NHR@FAU does not operate an A64FX system, the Software & Tools group started developing a Linux kernel module for the A64FX hardware barrier. Fujitsu published documentation and code (including tests) to write the kernel module. We are grateful to Stony Brook University for providing access to their OOKAMI cluster (see Acknowledgement) so we could do extensive testing and validation.
Today we release our version of the A64FX hardware barrier kernel module at Github under open source license (LGPL-3.0). The OOKAMI nodes use kernel 4.18, so updates might be required for more recent kernel versions.
We performed a simple benchmark of barrier synchronization time, comparing the GCC 11.2.0 OpenMP (software) barrier and the hardware barrier (Fujitsu user space library & our kernel module):
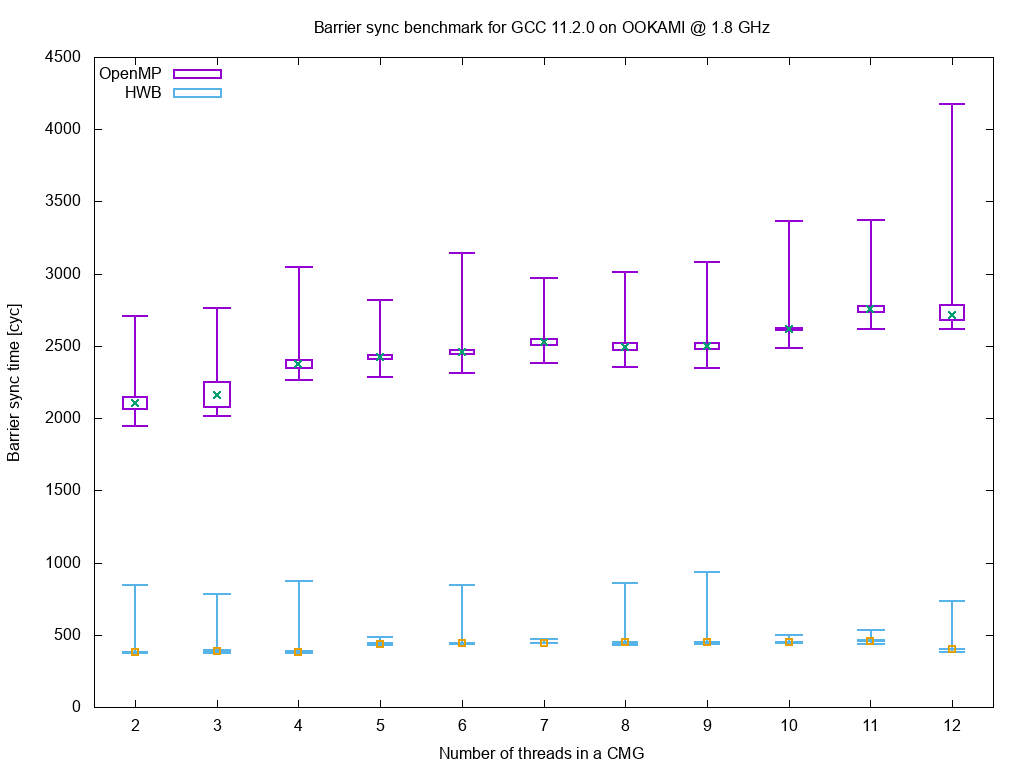
It is remarkable that the hardware barrier time is independent of the number of threads. It is about five times faster than the software implementation in the GCC OpenMP runtime.
The NHR@FAU group has previously done some research on performance modelling and optimization for the A64FX:
- C. L. Alappat, J. Laukemann, T. Gruber, G. Hager, G. Wellein, N. Meyer, and T. Wettig: Performance Modeling of Streaming Kernels and Sparse Matrix-Vector Multiplication on A64FX. 2020 IEEE/ACM Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS), GA, USA, 2020, pp. 1-7. PMBS20 Best Short Paper Award. DOI: 10.1109/PMBS51919.2020.00006 Preprint: arXiv:2009.13903
- C. L. Alappat, N. Meyer, J. Laukemann, T. Gruber, G. Hager, G. Wellein, and T. Wettig: ECM modeling and performance tuning of SpMV and Lattice QCD on A64FX. Concurrency and Computation: Practice and Experience, e6512 (2021). Available with Open Access. DOI: 10.1002/cpe.6512, Preprint: arXiv:2103.03013
If you have any questions regarding the A64FX hardware barrier kernel module, do not hesitate to write an e-mail to:
Thomas Gruber
Erlangen National High Performance Computing Center
Software & Tools Division
- Phone number: +49 9131 85-28911
- Email: thomas.gruber@fau.de
Acknowledgement:
The authors would like to thank Stony Brook Research Computing and Cyberinfrastructure, and the Institute for Advanced Computational Science at Stony Brook University for access to the innovative high-performance Ookami computing system, which was made possible by a $5M National Science Foundation grant (#1927880).