
One of our file servers experiences extremely high load since March 27. This is presumably caused by a user application with detrimental file access patterns, bringing the server to is knees. Unfortunately, this currently affects all users on all clusters and frontends; normal work is all but impossible at times. We are working on resolving the situation and apologize for any inconvenience.
The Tier3 clusters (Woody, TinyFAT, TinyGPU, and Meggie) are currently in emergency maintenance.
2024-03-28 13:20 All cluster are back in operation. A possibly faulty SAS cable has been replaced.
2024-03-29 08:00 Replacing the SAS cable did not (or at least not fully) fix the issue.
2024-04-19 We still see spikes from time to time …
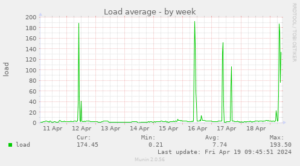
2024-04-24 Upgrading to Linux kernel 6.8 (from Ubuntu 24.04) did not improve the situation
2024-04-26 Unfortunately, by now we’re rather confident we’re hitting a kernel bug in the filesystem code here. We are preparing yet another data migration. This will take some time, and until this is finished, the problems will continue.
2024-05-21 We have now migrated /home/woody to another filesystem, and consider this problem solved. (Note: That does not mean that users cannot still kill the server due to bad work patterns. But the problem of it randomly not responding for an hour without any user causing much load is now solved.)