Improved performance of a GPU-accelerated Bayesian inference framework
Improved performance of a GPU-accelerated Bayesian inference framework (USI, Switzerland)
Background
During scalability tests of a C++ framework performing spatial-temporal Bayesian modeling unexpected slowdown was observed for increasing numbers of GPUs/MPI processes. The framework is based on a methodology called integrated nested Laplace approximations (INLA)1 which offers computationally efficient and reliable solutions to Bayesian inference problems. INLA is applicable to a subclass of Bayesian hierarchical additive models and our framework is particularly tailored to data with spatial-temporal association. A large part of the algorithm consists of solving an optimization problem which, in every iteration, requires independent and thus parallelizable function evaluations. Due to the inherent parallelism, we expected (almost) ideal strong scaling up to the number of necessary function evaluations per iteration. The computational kernel operation of each function evaluation is a Cholesky factorization of a large block tridiagonal symmetric positive definite matrix and a subsequent forward-backward solve. A block-wise factorization of each matrix was implemented for GPU that requires large memory transfers between GPU and main memory for each supernode of the matrix.
|
|
|
Analysis
It could be observed that some of the MPI processes exhibited much longer runtimes for comparable tasks while others seemed to be unaffected. Moreover, despite all operations cause the same workload, there is variation in the performance at each kernel invocation.
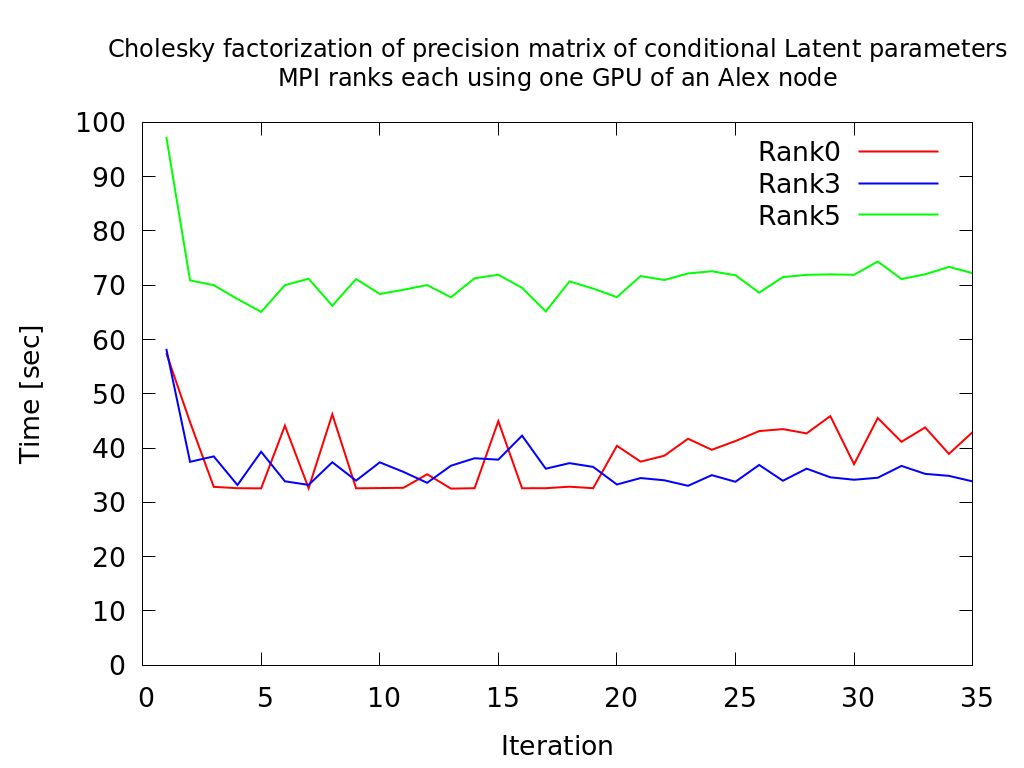
The CPU and GPU affinity was examined for all MPI processes. With increasing count of MPI processes and thus GPUs performing memory intensive operations, also the runtime differences increased. The application used the default affinity of the underlying MPI implementation.
Optimization
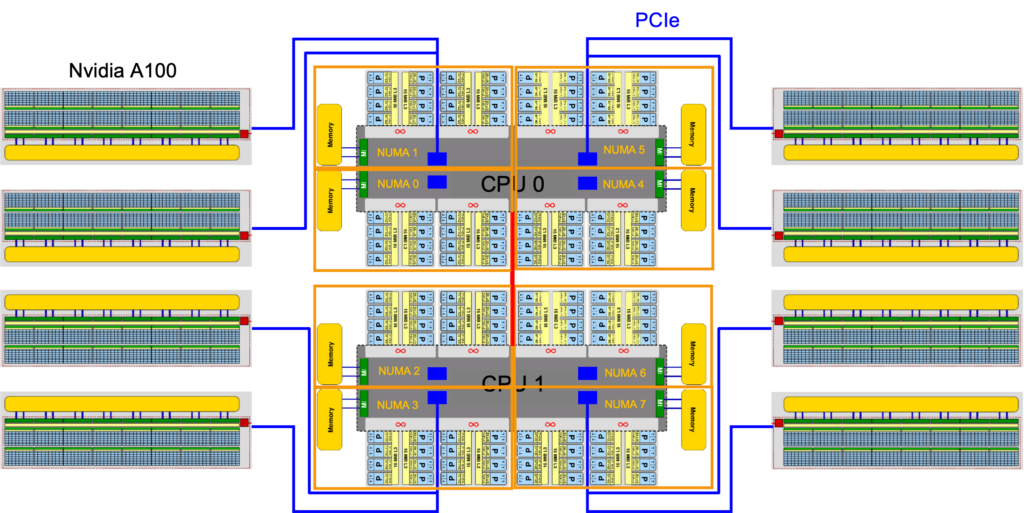
After studying the architecture of the GPGPU nodes on Alex it was possible to identify an affinity setup that significantly improves the performance of the implementation. The key steps included pinning the MPI processes in such a way that the employed hardware threads of the CPU are optimally connected to the specified GPU (same NUMA domains). Additionally, it was made sure that the memory intensive operations were equally distributed among the different NUMA domains.
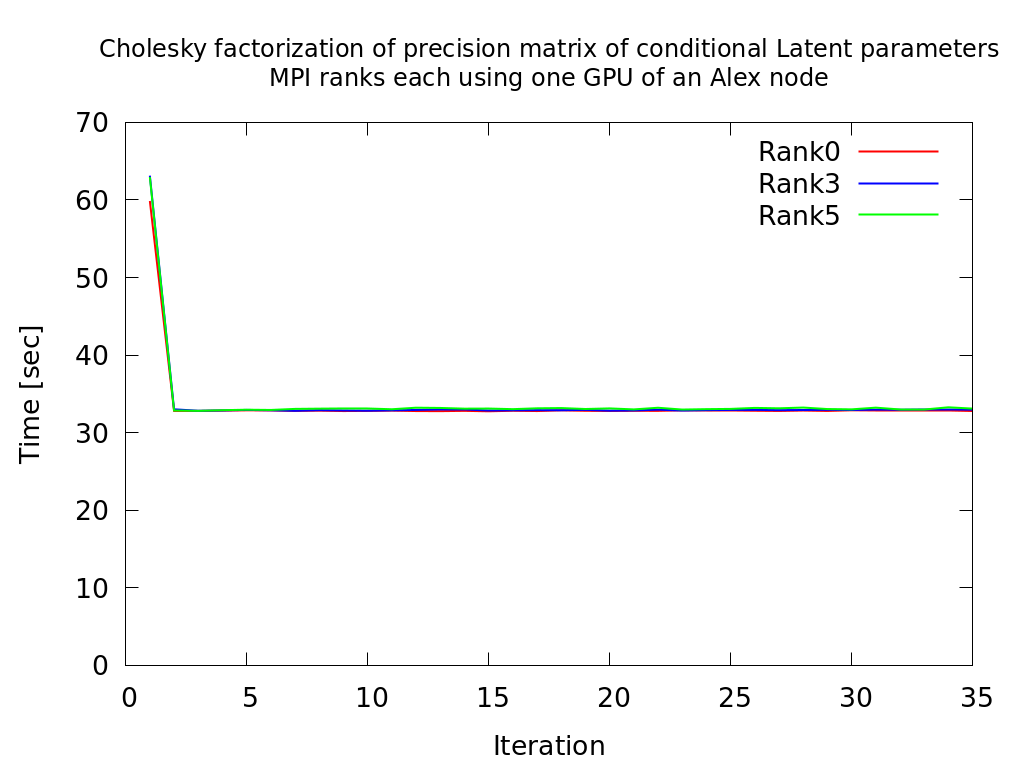
Summary
The performance of the single as well as multi-process version was significantly improved by implementing a customized affinity pattern. It is chosen such that the memory bandwidth between the assigned GPUs and CPUs is maximized for each MPI process while also ensuring load balancing between NUMA domains.
|
|
|
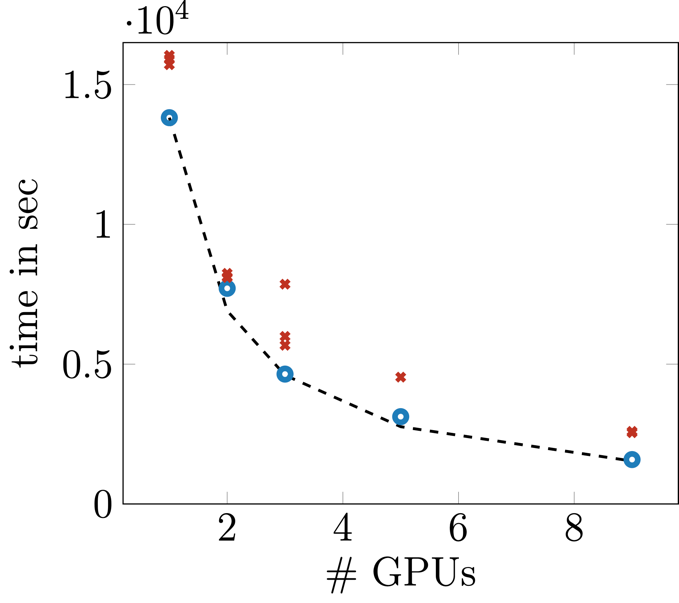
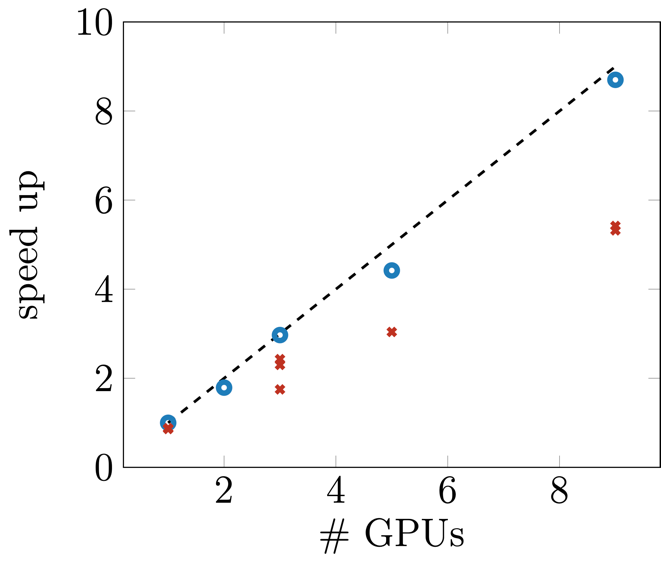
The NUMA and GPU topology of an Alex node (in NPS4 mode) is non-optimal as it connects 2 GPUs to one NUMA domain while leaving one “empty” (no GPU attached). For jobs scheduled on the GPU that gets the hardware threads assigned located in the empty domain, the access to system memory will be slower compared to the other GPU in the pair.
References
- Gaedke-Merzhäuser, L., van Niekerk, J., Schenk, O., & Rue, H. (2022). Parallelized integrated nested Laplace approximations for fast Bayesian inference. arXiv preprint arXiv:2204.04678.
- Rue, H., S. Martino, and N. Chopin (2009). Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. Journal of the royal statistical society: Series b (statistical methodology) 71(2), 319–392