HPC User Report from S. Falk (Division of Phoniatrics and Pediatric Audiology)
simVoice – Numerical computation of the human voice source
The central objective of this project is the development of a three dimensional aero-acoustic numerical model (simVoice) for a prospective application in a clinical environment. The larynx model considers the fluid flow through the glottis, the vocal fold motions, and the resulting acoustic signal. Thereby, we solve the partial differential equations of the fluid flow by a Finite Volume (FV) and the acoustic field by a Finite Element (FE) method.
Motivation and problem definition
Voice research is mostly carried out with an experimental setup (synthetic or ex-vivo/in-vivo animal and human larynges) which includes high personal, material and financial costs in combination with: (1) limited access to a few specific positions within the larynx, and (2) limitation to a few parameters. The main advantage of a numerical approach compared to the experimental investigations is the high spatial and temporal access to the flow as well as acoustic quantities and the generated acoustic source terms.
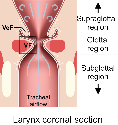
The challenge to develop a 3D aero-acoustic model for the clinical application is the need of a short simulation wall-time in combination with sufficient accuracy of the fluid dynamic characteristics within the larynx to capture all the essential acoustic sources.
Methods and codes
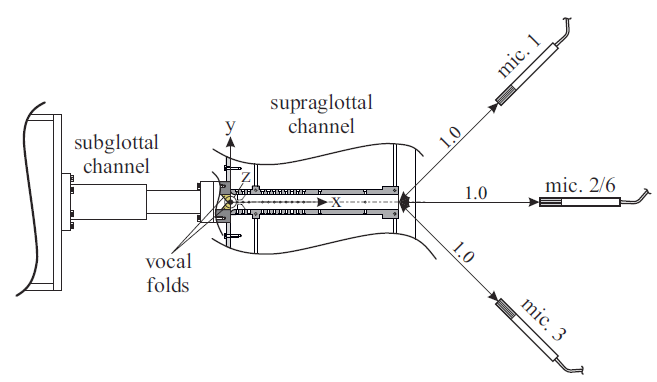
The simVoice-model is a hybrid model. It consists of a fluid dynamic simulation model with an external driven vocal fold motion, based on the 3D FV method, and an aero-acoustic model, based on the 3D FE method. The commercial computational fluid dynamic (CFD) software STAR-CCM+ (Siemens) was used for the fluid dynamic calculations, and the research-driven simulation tool CFS++ for the acoustic computation.
The numerical model of simVoice considers the vocal folds, the ventricular folds and various vocal tract geometries based on a synthetic vocal fold model. The oscillation of the vocal folds, identified from in-vivo and ex-vivo high-speed imaging, is externally forced. The fluid dynamic simulation model uses the Large Eddy Simulation (LES) turbulence model to solve the incompressible fluid dynamic equations.
After that, the acoustic source terms are computed on the flow grid and a conservative interpolation to the acoustic grid, on which we solve the perturbed convective wave equation to obtain the acoustic field, is conducted. simVoice is currently optimized concerning computing time and complexity, considering the computational grid resolving all relevant turbulent scales. This optimization will achieve the prospective clinical application of the hybrid model simVoice.
Results

In the first step, the fluid dynamic and aero-acoustic models of simVoiceare validated with the experimental results to obtain physical correct acoustic source terms and results. After applying an efficient workflow between STAR-CCM+ and CFS++, reaching the postulated short wall-time for a clinical application and attaining a highly accurate overall model an extensive study on effects of various vocal fold motions, glottis geometries and vocal tracts on the acoustics will be following. As one of the last steps, simVoice< will be transferred to real phonation and verified with clinical data.
The fluid dynamic simulation part of simVoice is performed with seven nodes on the Emmy or Meggie cluster. With the mentioned use of HPC resources, the wall time of the LES simulations for the necessary ten vocal fold oscillations range up to 330 hours.
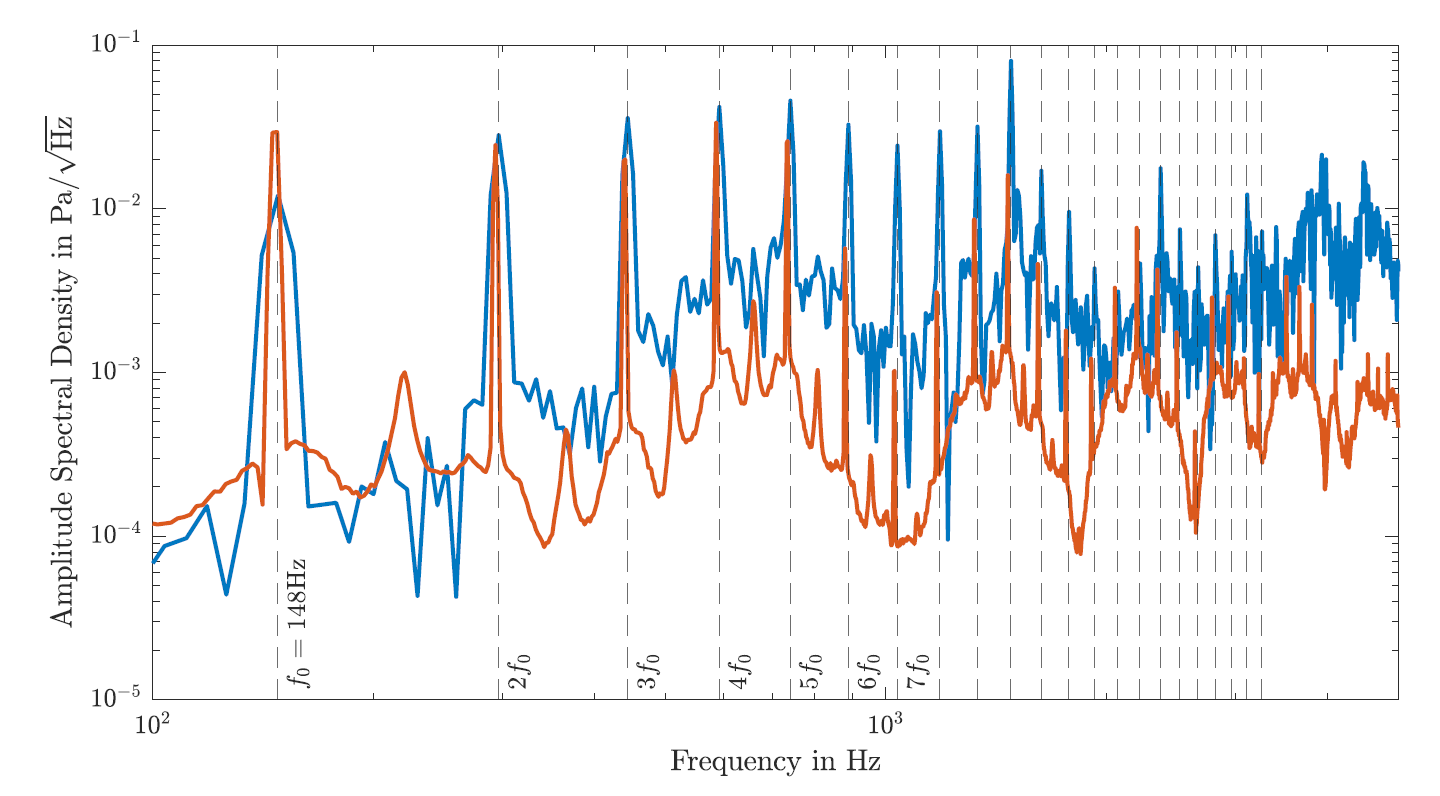
The innovative scientific aspects of simVoice are: (1) Analysis of the magnitude of dissolving the time-dependent turbulent fluid flows to obtain physical correct acoustic source terms; (2) To gain insight in the cause and effect of the vocal folds motion, fluid flow and acoustics; (3) An extensive study of the impact of various glottis geometries, vocal fold motions and vocal tracts on the acoustic signal.
Outreach
The project is running since August 2016.
- S. Kniesburges, Fluid-Structure-Acoustic Interaction during Phonation in a synthetic larynx model. Dissertation, Shaker, 2014
- H. Sadeghi, S. Kniesburges, M. Kaltenbacher, A. Schützenberger, and M. Döllinger. Computational models of laryngeal aerodynamics: Potentials and numerical costs. Journal of Voice, 2018, DOI:10.1016/j.jvoice.2018.01.001
- H. Sadeghi, S. Kniesburges, and M. Döllinger. Aerodynamic impact of the ventricular folds in computational larynx models. Journal of Acoustical Society of America, 2019, DOI:10.1121/1.5098775
- H. Sadeghi, S. Kniesburges, S. Falk, M. Kaltenbacher, A. Schützenberger, and M. Döllinger. Toward a Clinical Applicable Computational Larynx Model. Appl. Sci., 2019, DOI:10.3390/app9112288
- S. Falk, S. Kniesburges, S. Schoder, B. Jakubaß, P. Maurerlehner, M. Echternach, M. Kaltenbacher, and M. Döllinger. 3D-FV-FE Aeroacoustic Larynx Model for Investigation of Functional Based Voice Disorders. Front. Physiol., 2021, DOI:10.3389/fphys.2021.616985
Funding
The project is currently funded (02/2018 – 02/2021) by the Deutsche Forschungsgemeinschaft (DFG) under project no. DO 1247/10-1.
Cooperation
Prof. Dr. techn. Dr.-Ing. habil. Manfred Kaltenbacher – Institute of Mechanics and Mechatronics at the Vienna University of Technology: Responsible for the interpolation of the fluid dynamic results to the acoustic grid, and the solving of the perturbed convective wave equation to obtain the acoustic field. This part of the project is funded by Der Wissenschaftsfonds (FWF) of Austria under the project no. I 3702.
Researcher’s Bio and Affiliation
Sebastian Falk obtained his Master degree in Mechanical Engineering at the Friedrich-Alexander University Erlangen-Nürnberg (FAU) and is currently a PhD student and scientific assistant under the supervision of PD Dr.-Ing. Stefan Kniesburges and Prof. Dr.-Ing. Michael Döllinger (Head of research) at the division of Phoniatrics and Pediatric Audiology at the Department of Otorhinolaryngology, Head and Neck Surgery of University Hospital Erlangen and Medical Faculty of FAU.