Retrieving short monophonic queries in music recordings is a challenging research problem in Music Information Retrieval (MIR). In this study, we present a data-driven approach based on Deep Neural Networks to learn a “salience” representation which in turn improves the retrieval results.
Motivation and problem definition
In jazz music, given a solo transcription, one retrieval task is to find the corresponding (potentially polyphonic) recording in a music collection. Many conventional systems approach such retrieval tasks by first extracting the predominant F0-trajectory from the recording, then quantizing the extracted trajectory to musical pitches and finally comparing the resulting pitch sequence to the monophonic query. In this project, we introduce a data-driven approach that avoids the hard decisions involved in conventional approaches: Given pairs of time-frequency (TF) representations of full music recordings and TF representations of solo transcriptions, we use a DNN-based approach to learn a mapping for transforming a “polyphonic” TF representation into a “monophonic” TF representation. This transform can be considered as a kind of solo voice enhancement. Besides retrieval applications, this TF representation can also serve as a preprocessing step in various other MIR-related tasks involving polyphonic music, e.g., music transcription or fundamental frequency estimation.
Methods and codes
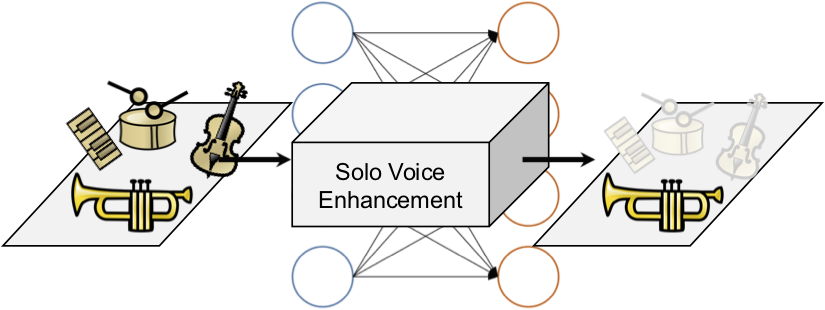 In our approach, we model the solo voice enhancement step as a regression problem and use a DNN as a regressor. The input to the DNN is the “noisy” TF representation of jazz music recordings including the superposition of the soloist and accompanying musicians (e.g., drums, piano). The targeted output is a TF representation where the soloist is enhanced. As for the labeled data, we use annotated music recordings of famous jazz solos from the Weimar Jazz Database (http://jazzomat.hfm-weimar.de). The network is trained by using a combination of the open-source libraries Theano (https://github.com/Theano/Theano) and keras (https://keras.io) which we then run on the TinyGPU cluster.
In our approach, we model the solo voice enhancement step as a regression problem and use a DNN as a regressor. The input to the DNN is the “noisy” TF representation of jazz music recordings including the superposition of the soloist and accompanying musicians (e.g., drums, piano). The targeted output is a TF representation where the soloist is enhanced. As for the labeled data, we use annotated music recordings of famous jazz solos from the Weimar Jazz Database (http://jazzomat.hfm-weimar.de). The network is trained by using a combination of the open-source libraries Theano (https://github.com/Theano/Theano) and keras (https://keras.io) which we then run on the TinyGPU cluster.
Results
From the experiments we conclude that in the case of jazz recordings, solo voice enhancement improves the retrieval results. Furthermore, the DNN-based and current state-of-the-art approaches perform on par in this scenario of jazz music and can be seen as two alternative approaches. In future work, we would like to investigate if we can further improve the results by enhancing the current data-driven approach, e.g., by incorporating temporal context frames or testing different network architectures.
A web-based demo can be reached under the following address:
https://www.audiolabs-erlangen.de/resources/MIR/2017-ICASSP-SoloVoiceEnhancement
Outreach
The International Audio Laboratories Erlangen are a joint institution of the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) and the Fraunhofer-Institut für Integrierte Schaltungen IIS.
This work has been supported by the German Research Foundation (DFG MU 2686/6-1) and published in the following article:
- Stefan Balke, Christian Dittmar, Jakob Abeßer, and Meinard Müller: Data-Driven Solo Voice Enhancement for Jazz Music Retrieval, In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP): 196-200, 2017. Web-Demo: https://www.audiolabs-erlangen.de/resources/MIR/2017-ICASSP-SoloVoiceEnhancement
In a follow-up work, we adapted a similar architecture to the task of transcribing walking bass lines in jazz music:
- Jakob Abeßer, Stefan Balke, Klaus Frieler, Martin Pfleiderer, and Meinard Müller: Deep Learning for Jazz Walking Bass Transcription, In Proceedings of the AES International Conference on Semantic Audio: 202-209, 2017. Web-Demo: https://www.audiolabs-erlangen.de/resources/MIR/2017-AES-WalkingBassTranscription
Researcher’s Bio and Affiliation
Stefan Balke studied electrical engineering at the Leibniz Universität Hannover. Since 2014, he is pursuing his PhD under the supervision of Prof. Dr. Meinard Müller (Lehrstuhl für Semantische Audiosignalverarbeitung) at the International Audio Laboratories Erlangen.