BMBF projects StroemungsRaum and DaREXA completed—with numerous results
Two of the BMBF-funded projects at the NHR@FAU recently concluded with the submission of their closing reports: StroemungsRaum and DaREXA-F. Both activities ran for about three years and have now been successfully completed. In the following, we briefly describe the contributions of NHR@FAU to th4se
StroemungsRaum
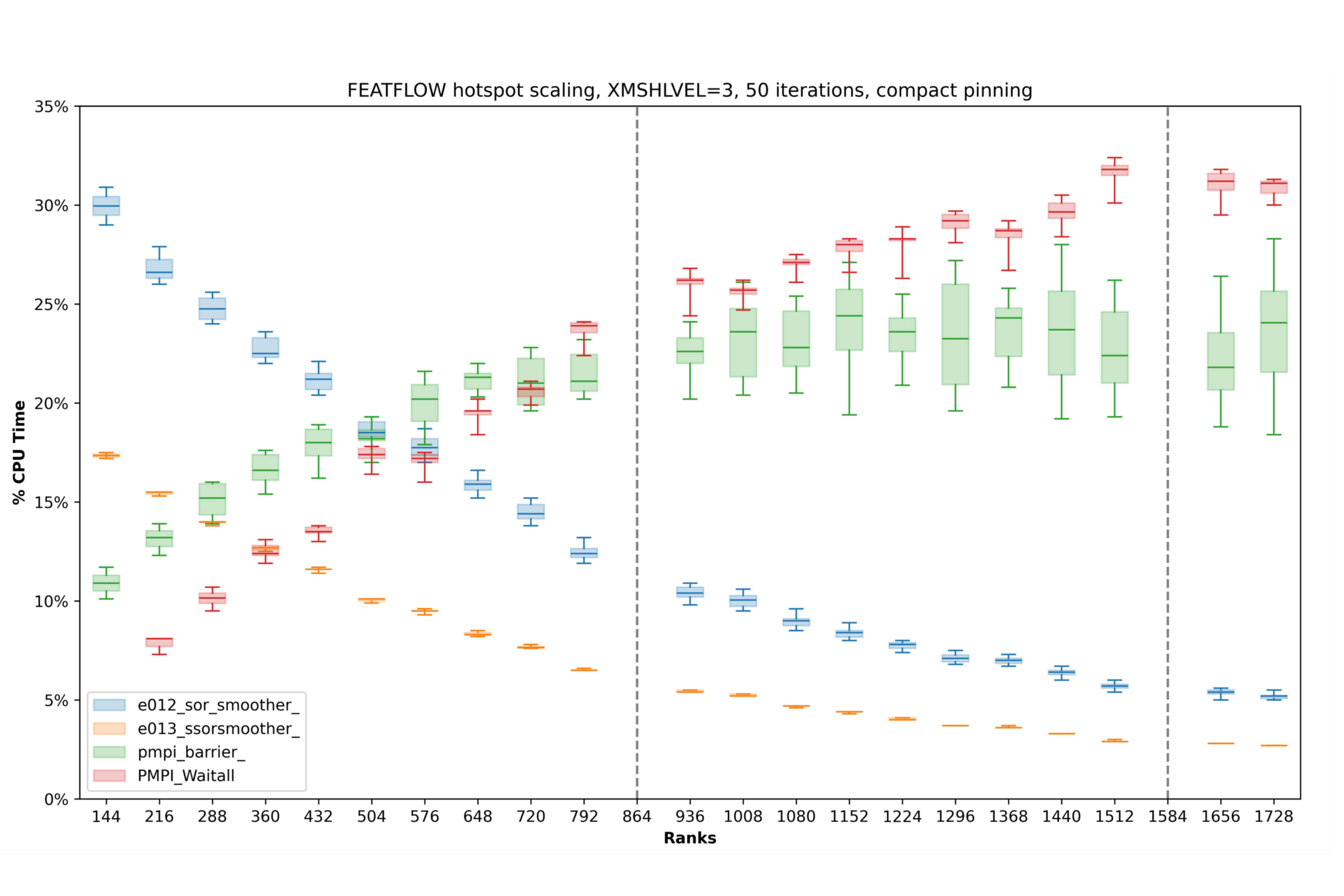
Within the StroemungsRaum project, new and extended solver approaches for spatially and temporally parallel flow simulations were developed, ported to modern HPC and GPU architectures, and incorporated into both the FEATFLOW and StrömungsRaum® codes. Performance analysis revealed that the SOR multigrid smoothing routines in FEATFLOW constituted the primary bottleneck at low MPI process counts. As process counts scaled up, global MPI barriers became increasingly dominant, accounting for the majority of runtime beyond 1000 processes.
To address this, the communication scheme was redesigned around non-blocking MPI calls—a change applied also to the Vanka smoothers in the modernized solver toolbox FEAT3—, enabling effective overlap of communication and computation and significantly improving scalability. In parallel, it became evident that the rectangular block-sparse matrices produced by FEAT3 are ill-suited for cuSPARSE and frequently prevent full utilization of GPU resources. In response, hand-optimized CUDA kernels were developed in collaboration with TU Dortmund University. These kernels delivered higher performance for the relevant computational patterns and underscored the importance of a flexible, capable prototyping framework.
The StroemungsRaum project has already resulted in a joint paper as part of the The International Journal of High Performance Computing Applications, and two additional publications are also in the works.
DaREXA-F
The project DaREXA-F was aimed at data reduction for exascale applications in fusion research. The participating parties achieved key milestones and responded flexibly to the challenges by the GENE code. The deployment of the infrastructure on the “Fritz,” “Alex,” and “Helma” clusters, as well as the expansion of performance tools for modern architectures such as NVIDIA Grace and Intel Sapphire Rapids, were successfully implemented. In addition, WINIC, a new tool for cycle-accurate measurement of individual instructions, was developed. Milestone 3.1 was adapted: Instead of traditional proxy development, in-depth kernel analyses at the assembly level and a specialized ZFP proxy benchmark were used to precisely evaluate performance gains from lossy compression in message passing.
From a technical standpoint, 4D data arrays were integrated into the ZFP library, and GPU-based compression was significantly improved, leading to increased performance. The results also contributed to scientific publications. Overall, the goals of model-based optimization and exascale readiness of GENE were successfully achieved and made internationally visible.
Thus, the participating parties were able to successfully fulfill the core objectives of DaREXA-F: model-based optimization and GENE’s exascale readiness. Furthermore, additional results went even beyond the project objectives. These achievements resulted in several scientific publications, including a nomination as a “Best Paper Candidate” at the IPDPS 2024 conference. A joint project poster was successfully presented at the “Supercomputing 24” conference, and two additional papers are currently under review at international conferences. Following the DaREXA-F project, the project partners also met with the Georgia Institute of Technology to exchange research findings and plan a joint publication.